-
1/13 프론트엔드 온보딩 인턴십 내용 정리.원티드 프리온보딩 2023. 1. 13. 21:33
1. Redux가 개발된 배경
Redux는 하나의 디자인 패턴으로서 MVC패턴이 가지고 있던 문제점을 해결하기 위해 만들어졌다.
디자인 패턴이란 거장한 것이 아니라 문제를 해결하기 위한 모범 답안 및 사례라고할 수 있는데, 디자인 패턴은 작은 문제를 해결하기 위한 작은 방법부터 거대한 문제를 해결하기 위한 크고 거창한 방법까지 그 종류가 다양하다.
보통 거대한 디자인 패턴은 작은 디자인 패턴 사례들의 집합으로 이루어지며 Redux 역시 기존의 MVC 디자인 패턴이 가지고 있던 문제를 개선하기 위한 디자인 패턴 중 하나이다.
그렇다면 기존 MVC 패턴의 문제점을 파악할 필요가 있다.
이전 포스트에서 기록했듯이 어플리케이션 설계의 근본은 '관심사의 분리'인데, MVC 패턴은 관심사를 Model, View, Controller라는 세 종류로 나눈 것이다.
여기서 각 요소가 의미하는 바는 무엇일까?
1) 말 그대로, 사용자에게 보여지는 UI를 의미하며, 사용자의 요청을 최선에서 감지하는 역할을 수행하고 그 요청을 Controller에게 전송한다.
2) Controller는 모델의 변화를 요청받아 그 요청을 수행하거나 Model에게 변화를 위임하는 역할을 수행한다.
3) Model은 데이터 및 데이터를 수정하는 요소를 의미하며 Model의 변화를 View로 전달하여 UI가 업데이트될 수 있도록 돕는다.
이렇게 이론적으로는 순차적인 데이터의 변화 흐름 구조를 가지고있는 것처럼 보이나 실제로 MVC는 각 요소들이 순차적이 아니라 양방향으로 변화를 요청 및 연쇄적으로 변화를 유발한다는 단점이 있었다.
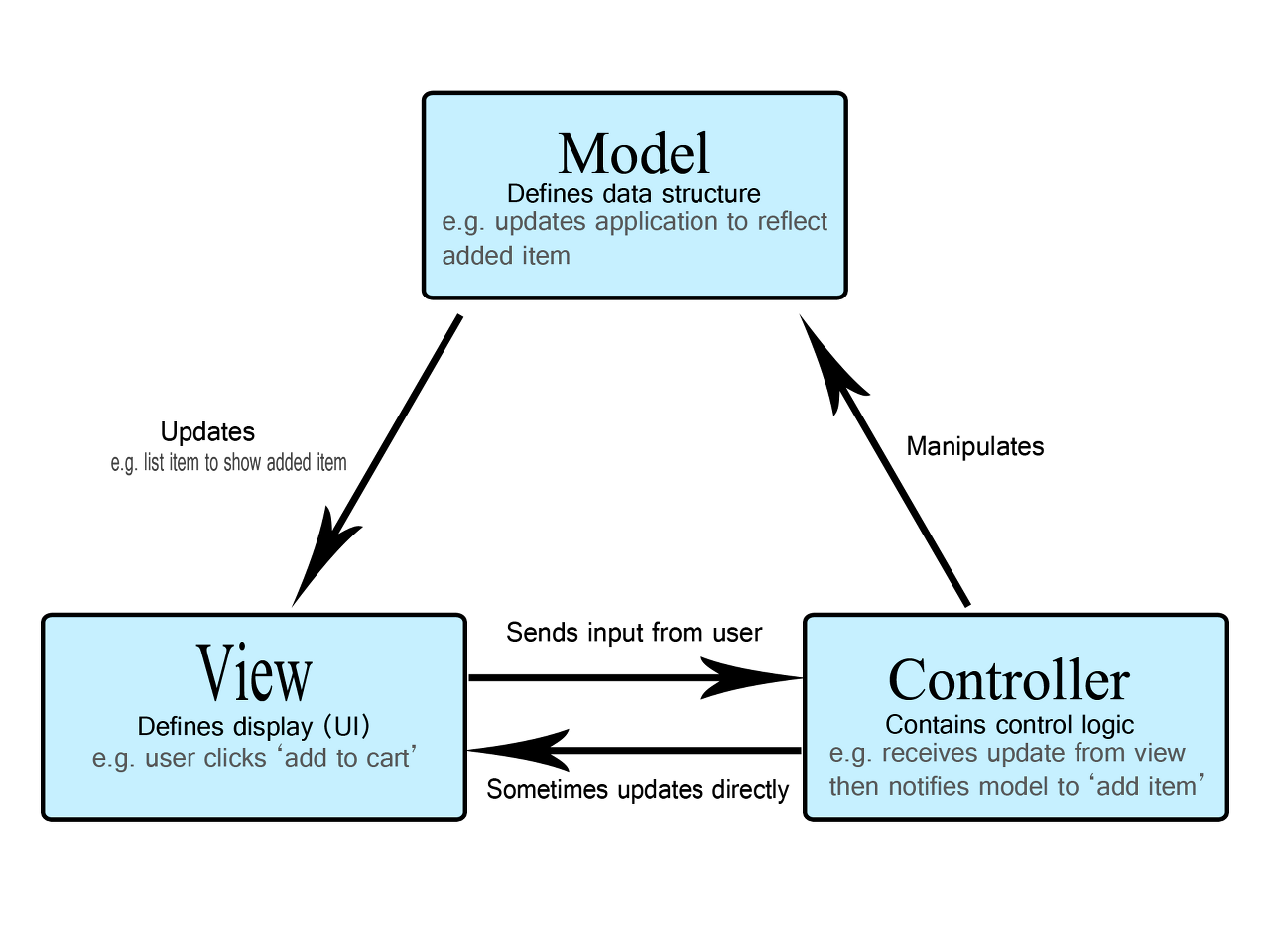
사진처럼 MVC에는 순차적 흐름이 아닌 view와 controller가 양방향으로 데이터를 전달하게 되는 일이 발생했다. 
또한, model과 view가 양방향으로 데이터를 주고받으며 연쇄적으로 불필요한 view의 업데이트를 요구하는 문제점도 존재했다. 위의 사진 예시같은 MVC 패턴의 문제들로 MVC 패턴으로 설계된 어플리케이션의 가장 큰 단점은 연쇄적이고 불필요한 view와 controller간, 또는 model과 view 사이의 데이터 전달과 업데이트였으며 때문에 사용자에게 잘못된 UI를 보여줄 가능성이 존재했다.
Redux는 이러한 문제를 해결하기 위해 flux 패턴을 사용하여 제작된 데이터 처리 패턴이다.
2. Flux 패턴이란?
Flux 패턴은 단순하고 단방향인 데이터 전달 흐름을 구현한 디자인 패턴이다.
이 패턴은 Action, Dispatcher, Store, View의 네 가지 요소로 이루어지며 이 순서대로 데이터가 전달된다.
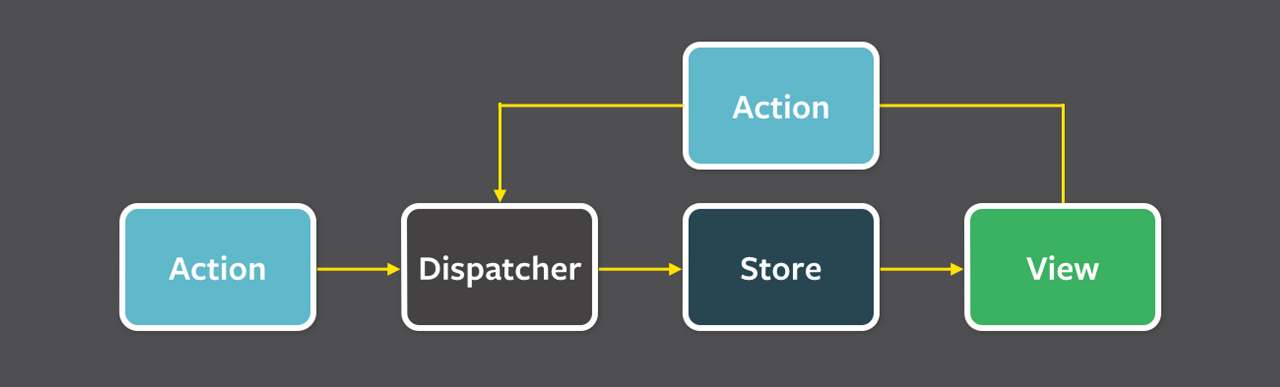
Flux 패턴에서 모든 action은 결국 view에서 시작하기 때문에 원형 구조라고 볼 수도 있다. 중요한 것은 각 요소들이 양방향이 아닌 정해진 순서를 지키면서 데이터가 흐른다는 것. Flux에서 각 요소가 의미하는 바는 이렇다.
1) action은 어떤 변화를 발생시킬지 정의하며, 그 변화의 종류와 변화시킬 값을 속성으로 가진 객체이다.
2) dispatcher는 action을 전달하는 단순한 전령이다. 다만, 이 dispatcher는 어플리케이션에서 딱 하나만 존재하기 때문에 모든 action의 흐름을 파악하고 있으며 그 흐름을 추적을 하기에 용이하다.
3) store는 데이터의 상태를 보관하고 있는 저장소이다. 이 저장소에서 dispatcher가 전달한 action이 가지고 있는 변화의 종류 및 그 값에 따라서 데이터를 변화시키고 그 값을 반환한다.
4) view는 그 데이터의 상태를 UI로서 보여주는 요소이다. SPA 어플리케이션으로 치면 컴포넌트에 해당할 것이다.
이렇게 Flux 패턴은 단방향의 흐름과 MVC 패턴보다 좀 더 명확한 각 요소들의 구조와 역할으로 데이터의 흐름을 좀 더 명확하게 하여 개발자들이 보다 더 버그의 위험성이 낮은 어플리케이션을 설계할 수 있도록 큰 도움을 주었다.
3. Redux가 추구하는 핵심 가치와 원칙은?
결국 Redux는 javascript로 만든 어플리케이션을 위한 예측가능한 상태 컨테이너 및 관리 도구로서 만들어진 것이다.
이 예측가능함이란 것은 그 구조가 단순하기 때문에 얻을 수 있는 중요한 속성이자 장점이라고 할 수 있다.
여기서 Redux의 원칙을 좀 더 파악하면 이 Redux라는 것이 어떤 구조를 차용하고 있는가를 유추해볼 수 있다.
1) Redux는 'Single source of truth'이라는 원칙을 따른다. 이 원칙은 모든 전역 상태는 트리구조로 이루어져 하나의 부모를 가진다는 것이다. 간단하게 Redux를 사용해본 사람은 전역 상태들이 reducer라는 이름으로써 이루어지고 이 reducer들은 전부 하나의 store이라는 객체인 저장소 안에서 이루어진다는 것을 경험적으로 알 것이다. 이 구조는 '진실은 하나로부터 나온다'라는 이 철학을 잘 구현한 것으로서 하나의 부모가 모든 전역 객체를 자식으로 갖는 트리의 형태를 갖는다. 따라서, 구조를 파악하기 용이하고 간단해진다.
2) 'State is read-only'이라는 원칙이 있다. 이 원칙은 한 가지 방법을 예외하고는 전역 상태를 바꿀 수 있는 방법을 전혀 제공하지 않는다는 것이다. 간단하게 말해서 전역 객체에 다른 상태를 할당하거나 조작하는 방법으로 이 상태를 바꿀 수 없다. Redux는 단지 action과 dispatcher를 통한 방식으로만 전역 객체의 변경에 대한 접근을 허용하며, 접근 후에도 단순한 할당이 아닌 reducer가 반환하는 값으로만 전역 상태가 변화할 수 있도록 설계되었다. 즉, 오직 한가지 방법만을 제외하면 Redux의 상태는 '읽기 전용'의 성격을 갖는다.
3) 'Changes are made with pure function'이라는 원칙을 따른다. Redux에서 전역 상태의 값을 변화시키는 직접적 주체인 reducer는 pure function, 즉, 순수함수로만 변경이 가능하다는 것이다. 그렇다면 순수함수란 무엇인가. 그것은 동일한 입력을 받았을 때, 항상 동일한 출력을 하는 함수를 말한다. 아래에 예시를 들겠다.
const plusOne = (x) => x + 1;위의 함수는 순수함수이다. 어떤 값이 들어오든 그 값에 1을 더한 값을 결과로 출력하며 그 사실에는 어떠한 예외의 여지가 없다. 이것이 바로 순수함수이다.
const plusRandomNumber = (x) => x + Math.random();반면, 위의 함수는 순수함수가 아니다. 입력값이 동일해도 출력의 값이 항상 달라질 수 있다. 이렇게 사이드이펙트(의도하지 않은 결과, 또는 의도)가 발생할 수 있는 함수가 바로 비순수함수이다.
즉, Redux에서 reducer는 동일한 입력에 동일한 출력을 보장하는 순수함수라는 특징을 가지며, 이는 정확한 상태관리를 위해 꼭 필요한 속성이기에 Redux는 이 철학을 철저하게 실천한다.
4. Redux의 구성요소는?
이 글에서는 그런 내용을 다루고자 하지 않는다.
그런 내용은 공식문서나 하다못해 블로그, 인터넷 강의에서 쉽게 찾아볼 수 있고 금방 그 구조가 변경되니 굳이 여기에 기록할 필요를 느끼지 못한다.
반면, 세션을 들으며 간단하게 배운 점이 있는데, action을 정의할 때 해당 action 변수에 어떤 문자열값을 할당할지에 대한 방법을 기록하고자 한다.
const COUNTER_INCREMENT = "counter/INCREMENT";위와 같은 방법이 많이 쓰인다고 한다.
먼저 action은 상수이며 상태변화에 대한 흐름의 시발점이기 때문에 강조될 필요가 있다.
따라서, 일반적으로 대문자와 언더바를 사용한 명명법을 사용한다.
그리고 할당된 값은 "전역상태의 이름/action이름"의 형태로 작성하는 것이 권고되는데, 하나의 어플리케이션에는 여러 전역상태(reducer)가 존재할 수 있기 때문에 각 상태에 비슷한 역할을 하는 action들 역시 충분히 존재할 수 있다.
따라서, 각 action의 대상을 구분하기 위해 /를 기준으로 앞에는 전역상태의 이름과 뒤에는 action의 이름을 넣는 것이 값을 지정하는 최적의 방법이다.
5. Middleware란 무엇인가?
세션에서는 미들웨어를 '프레임워크의 요청과 응답 사이에 추가할 수 있는 코드'라고 설명한다.
서버에서 컨트롤러와 레퍼지토리의 중간에 서비스 단계에서 처리되는 서비스 단계 비즈니스 로직들을 일반적으로 미들웨어라고 칭하지만, 그 외에도 명령의 요청과 응답 사이에 존재하는 수 많은 로직들 역시 '미들웨어'라고 칭할 수 있다.이 미들웨어의 특징은 각 요소들이 독립적이고 상호연결이 가능해야 한다는 점인데 쉽게 말하면 이 미들웨어들이 블럭처럼 조립하고 떼어질 수 있는 구조를 가져야 한다는 것이다.즉, 이 미들웨어들을 손쉽게 분리하고 추가할 수 있어야 한다는 것이며 Redux에서의 미들웨어는 action을 dispatch하고 그 action이 reducer로 전달되는 과정에서 수행되는 코드들이다.
결국, 이 미들웨어도 모듈화의 일종이기 때문에 관심사의 효과적인 분리를 위한 패턴 중 하나라고 할 수 있을 것이다.
6. Middleware를 구현할 수 있는 방법들.
만약 dispatch를 수행하기 전후로 log를 수행하고 싶다면 이러한 코드가 짜여진 미들웨어를 구현하면 된다.그 방법 중 가장 간단한 방법은 아래와 같다.
const increaseAction = increaseCounter(); console.log("dispatching", increaseAction); store.dispatch(increaseAction); console.log("next state", store.getState());dispatch 전에 action를 출력하고, 후에 변경된 전역 상태 값을 출력하는 간단한 미들웨어의 예시이다.
그러나 이렇게 dispatch 전후에 log를 출력하는 방식은 재사용성 측면에서 아주 좋지 않다.
function dispatchAndLog(store, action) { console.log('dispatching', action) store.dispatch(action) console.log('next state', store.getState()) }따라서, 위의 예시처럼 좀 더 개선된 방식으로 내부에 dispatch를 간접적으로 사용하고 전후로 미들웨어가 동작하도록 하는 함수를 선언 및 호출하는 방법이 존재한다.
그러나 이 방법 역시 dispatch를 직접적으로 사용하지 않기 때문에, 매번 이 함수만으로 모든 미들웨어 로직을 처리해야한다는 점에서 결합도가 상당이 높아 좋지 못한 예시라고 할 수 있다.
const originDispatch = store.dispatch; store.dispatch = function dispatchAndLog(action) { console.log('dispatching', action) const result = originDispatch(action) console.log('next state', store.getState()) return result }그래서 더욱 개선된 개념이 등장하는데, 위의 코드는 MonkeyPatching을 통해 미들웨어를 구현한 사례이다.
MonkeyPatching은 라이브러리, 프레임워크에서 제공하는 코드를 직접 수정해서 사용하는 것을 말한다.
여기서 이미 구현된 dispatch 함수에 직접 다른 함수를 선언하고 그것을 할당하여 dispatch가 실행될 때, 추가적인 로직이 실행될 수 있도록 하는 미들웨어를 구현한 것이다.
또한, 먼저 다른 변수에 원래의 dispatch 함수를 할당함으로서, 원래의 dispatch 함수가 담긴 변수를 미들웨어 함수 안에서 호출하여 미들웨어 로직의 온전함 역시 보장되었다.
하지만, 역시 이 방법도 결합도가 높기 때문에 위의 다른 예시처럼 다른 미들웨어 로직들을 추가, 제거하려면 수 많은 코드들의 변경 작업이 필요하게 된다.
또한, MonkeyPatching은 이미 구현된 코드들을 직접적으로 변경하므로 예측하지 못한 버그가 발생할 확률도 매우 높다.
function logger(store) { const next = store.dispatch; return function dispatchAndLog(action) { console.log('dispatching', action) const result = next(action) console.log('next state', store.getState()) return result } } function crashReporter(store) { const next = store.dispatch; return function dispatchAndReportErrors(action) { try { return next(action) } catch (err) { console.error('에러 발생', err); throw err } } } function applyMiddlewareByMonkeypatching(store, middlewares) { copiesOfMiddlewares = [...middlewares]; copiesOfMiddlewares.reverse() copiesOfMiddlewares.forEach(middleware => (store.dispatch = middleware(store))) } applyMiddlewareByMonkeypatching(store, [logger, crashReporter])이 방식은 이전의 예시에서 확장성을 좀 더 고려하여 개선된 방법이다.
미들웨어 함수를 여러개 선언해놓고 맨 밑의 함수에 이 미들웨어들을 배열 안에 넣어 인자로 전송함으로서 이 미들웨어들이 순차적으로 dispatch 함수를 확장할 수 있도록 해준다.
즉, 확장성 측면에서 다른 위의 예시들 보다 유리하며 코드의 유지보수 작업이 수월하지만 이 방법 역시 dispatch 함수에 직접적으로 미들웨어 함수를 할당하여 기능의 확장을 수행하기 때문에 결국 예상치 못한 버그가 발생할 확률이 존재한다는 점은 동일하다.
function logger(store) { return function wrapDispatchToAddLogging(next) { return function dispatchAndLog(action) { console.log('dispatching', action) const result = next(action) console.log('next state', store.getState()) return result } } } // arrow function style const logger = store => next => action => { console.log('dispatching', action) let result = next(action) console.log('next state', store.getState()) return result } // apply middleware function applyMiddleware(store, middlewares) { copiesOfMiddlewares = [...middlewares]; copiesOfMiddlewares.reverse() let dispatch = store.dispatch; copiesOfMiddlewares.forEach((middleware) => { dispatchEnhancer = middleware(store); dispatch = dispatchEnhancer(dispatch) }); return { ...store, dispatch } } applyMiddleware(store, [logger, crashReporter])그래서 이 MonkeyPatching을 해결하는 방법으로 위와 같이 currying 코드 패턴이 사용된다.
이 패턴은 함수를 부분적으로 사용할 수 있는 기법으로서, 먼저 인자를 전달 받은 함수가 이후에 다른 인자를 받아 각 상황에 맞는 결과를 반환할 수 있도록 해준다.
즉, 먼저 인자를 받은 함수가 이후에 다음 인자를 받는 함수를 반환하도록 할 수 있다는 것이다.
이를 통해, 위의 코드는 dispatch를 직접적으로 수정하지 않고 dispatch 함수를 할당받은 함수에서 미들웨어를 계속 확장해 나가는 방식을 취한다.
아래는 currying 패턴의 예시이다.
만약 두 수를 더하고 그 결과에 2를 곱한 값을 반환하는 함수를 제작한다고 하자.
const multiplyTwo = (x, y) => (x + y) * 2;그 식은 위의 함수처럼 만들 수 있다.
그러나 x와 y가 인자로 받아지는 시점을 분리하여 좀 더 동적인 패턴을 갖는 함수를 제작하고 싶을 수 있다.
const multiplyTwo = (x) => (y) => (x + y) * 2; const foo = multiplyTwo(1); const foo2 = foo(2);그런 경우는 위 코드처럼 표현 가능하다.
x를 먼저 받아 그 값을 클로저로서 기억하는 함수를 반환하고, 그 반환된 함수는 y를 인자로 받아 x와 y값을 가지고 최종 결과를 반환하는 함수를 제작하는 패턴이 바로 currying 방식의 간단한 예시이다.
이 방식은 다른 방식들보다 단계적이고 결합도가 낮은 미들웨어 확장 방식을 사용하기 때문에, 유지보수가 유리하며 다양한 상황을 가정하여 여러 계층의 미들웨어에서 발생하는 특정 상황에 reducer로 전달되는 요청을 차단하거나 흐름을 변경할 수 있다는 장점이 존재한다.
결국, 위 방식을 활용하면 dispatch를 감싸는 미들웨어에서 예상치 못한 버그의 가능성을 낮추면서 효과적으로 미들웨어의 기능을 확장해 나갈 수 있다.
위 방식을 차용한 가장 유명한 라이브러리가 바로 전역상태 관리에서 비동기 처리를 할 수 있도록 도와주는 Redux-Thunk이다.
PS. 본 내용의 출저는 원티드 프리온보딩 프론트엔드 인턴십의 세션 내용입니다.
'원티드 프리온보딩' 카테고리의 다른 글
1/20 프론트엔드 온보딩 인턴십 내용 정리. (0) 2023.01.23 1/16 프론트엔드 온보딩 인턴십 내용 정리. (0) 2023.01.20 1/10 프론트엔드 온보딩 인턴십 내용 정리. (0) 2023.01.10 1/6 프론트엔드 온보딩 인턴십 내용 정리. (0) 2023.01.07 1/3 프론트엔드 온보딩 인턴십 내용 정리. (0) 2023.01.04